这是一个历时5个多小时的故障处理过程,值得认真记录、反思。
事后详查发现,数据库16:00之前就出现大量锁表情况,16:07运维支撑群有用户反映系统慢,直到反馈系统彻底没法用了。下图显示,实际14:00以后就开始出现了较多的锁表情况。
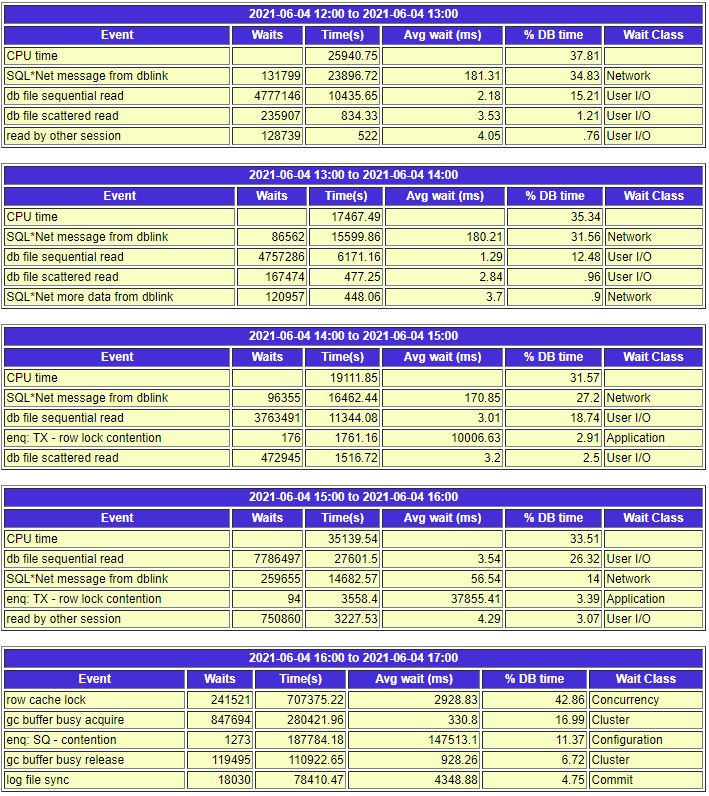
只是,14:00-16:00期间由于只是后台执行任务的锁表,并未明显影响到客户感知,相关的一线业务还可正常进行。
但是当这些执行失败的定时任务一个接着一个,反复重复执行,从而导致大量锁死时,会怎样呢?这会把整个库搞瘫痪。
相关的等待事件涉及到了大量的row cache lock、gc buffer busy acquire/release、SQ - contention、甚至波及到了log file sync
暂时还没查到具体的根因,但是基本可以确定就是那些定时任务---全量更新的物化视图失败、反复执行导致了大量的锁表,直到即使杀会话,也需要大量的回滚才能恢复,此时积压的回滚事务已经达到了极大的数量,仅凭数据库自身已难以恢复正常。
此时的数据库业务SQL已经无法正常执行,如下图所示。
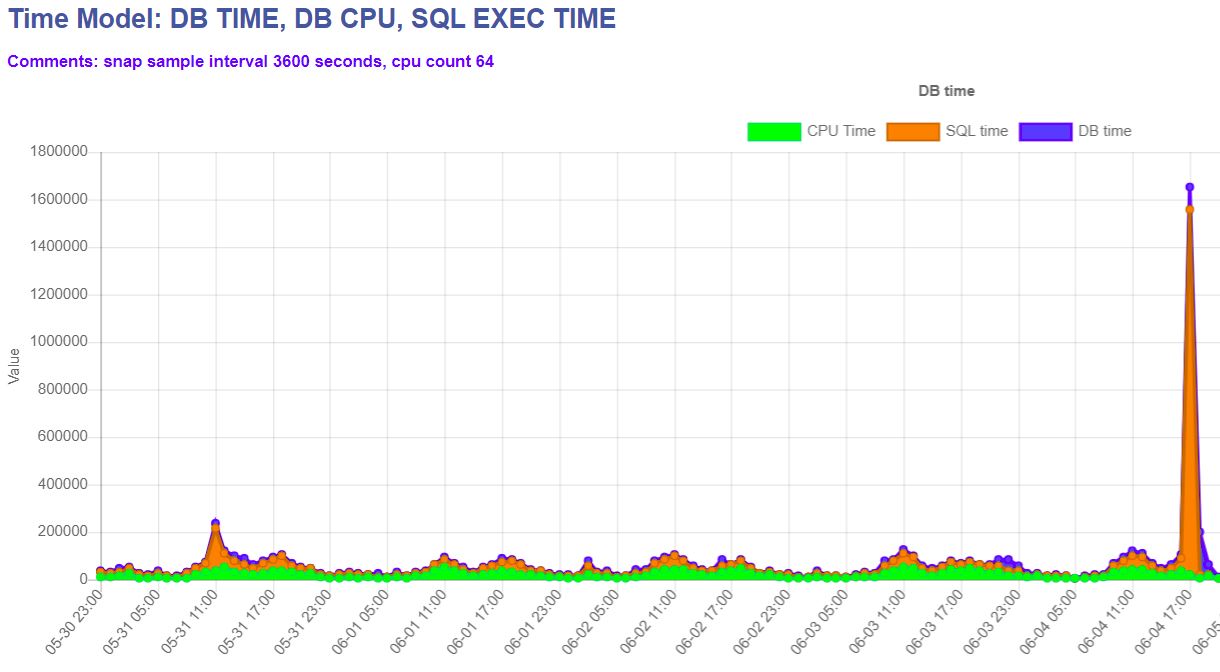
此时因为数据库自身已经无法自行尽快回滚所有积压的大量事务,在各方压力、催促之下,采用了重启数据库的方法,正常关库事件很长,采用了shutdown abort的方式,当时并未意识到这样做起库同样会面对大量事务回滚的情况,实际是没用的。
通过关库起库无法奏效,此时要求项目停止所有的应用,排查所有的定时任务、物化视图等,能杀的杀死,能关的先关掉。
甚至无奈之下同意了项目方面重启主机的做法,现在看来是无用功,呵呵。
也一度怀疑底层存储是否出了问题,让厂家确认了,没有问题。实际那时最大的等待事件是并发问题,如第一图所示排进前五的io等待事件只有log file sync的4.75%。
数据库实时监控工具oratop给了我很大的帮助,它实时向我展现着当前的数据库整体运行情况,大量的等待事件都是秒级以上,此时是万万没法接入应用的,在停掉了所有应用之后,仍然是那些大量的等待事件,涉及到各个用户的del、upd,尽管此时已经禁用了所有的用户!这说明redo有大量的已提交del、upd事务需要前滚,甚至会继续产生锁!
再继续看看下图,此时的数据库整体情况。
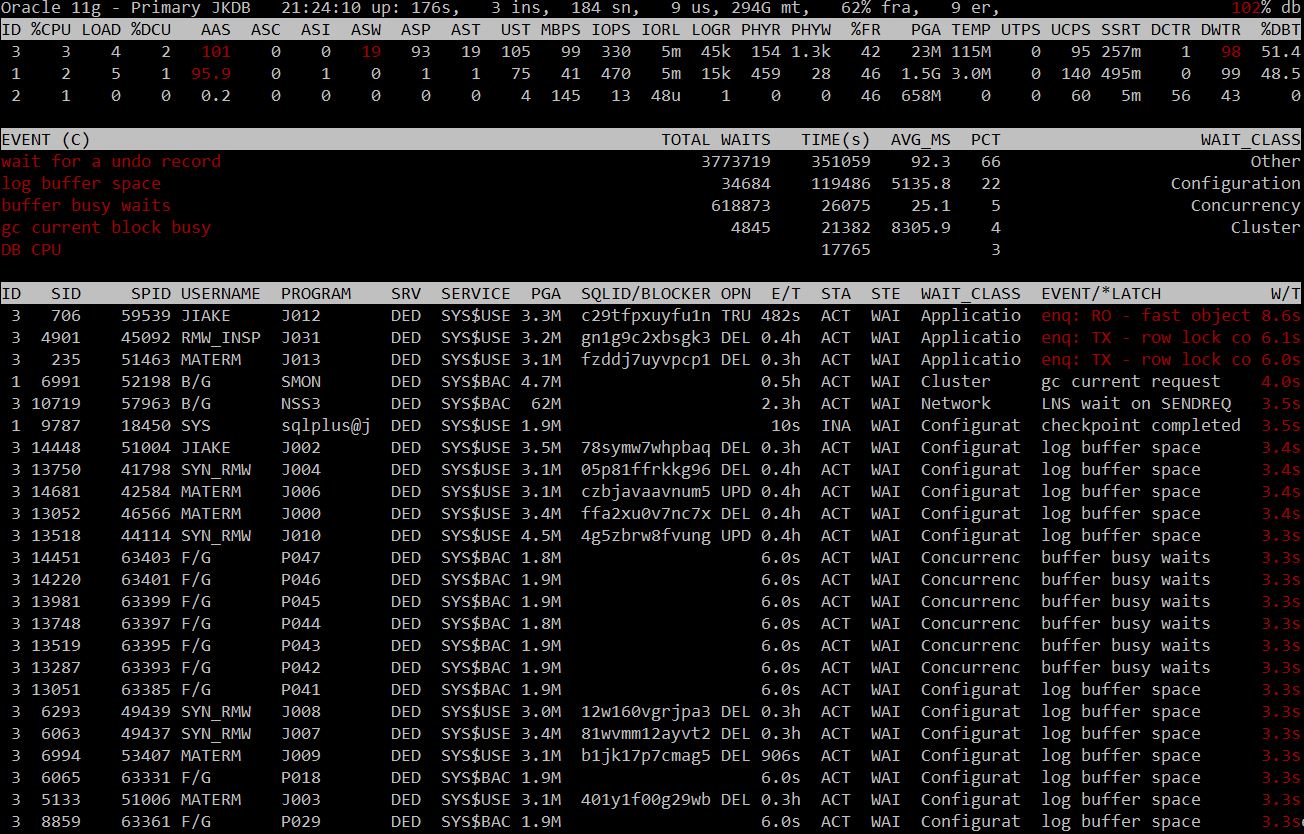
数据库最大的等待事件尽管是那些大量的前滚事务,但是这并不是他们慢的根本原因,数据库66%的时间在用于回滚事务,wait for a undo record !
这是一个3节点集群,单节点64CPU,内存也足够,数据库重启后大量事务回滚,会导致问题吗?此时竟然遭遇了一个oracle的大BUG。
---未完待续
大量事务并发回滚彻底堵塞数据库(1)

liking
这个人很懒,什么都没留下
文章评论